Neuron-level Interpretation of Deep NLP Models: A Survey
Neuron-level Interpretation of Deep NLP Models: A Survey
总述
- motivation
- 随着深度神经网络在各个领域的激增,对这些模型的可解释性的需求也在增加
问题
- 在网络的神经元中学习了哪些概念?
- 是否有专门学习特定概念的神经元?
- 网络神经元内的知识是如何局部/分布和冗余地保存的?
好处
通过识别与预测相关的神经元来控制偏差和操纵系统行为
通过删除不太有用的神经元来进行模型蒸馏
通过选择神经元来进行有效的特征选择
- 通过用重要神经元引导搜索来进行神经结构搜索。
基础定义
聚焦神经元:学习单个概念的单个神经元
群神经元:将组合起来表示一个概念的一组神经元
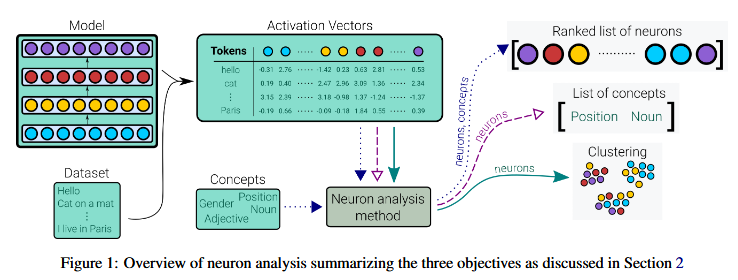
发现和理解网络中神经元的方法
方法
- 可视化 - Visualization
- 基于语料库
- 基于探究
- 基于因果关系
- 杂项
Visualization 可视化
- 定性以及主观。
- 由于大量的人为参与,它无法扩展到整个网络。
- 很难解释在不同环境中获得多个角色的多义神经元。
- 它在识别组神经元方面无效。
- 并非所有神经元都是视觉上可解释的。
Corpus-based Methods 基于语料库
- 汇总数据激活的统计数据来发现神经元的作用
- 基于语料库的方法是全局解释方法,因为它们解释了神经元在一组输入中的作用
- 将神经元作为输入并识别神经元已经学习的概念的方法(概念搜索)
- 简单来说,早期是 “看神经元对哪些 5 个词的组合最敏感,然后人来猜它代表什么”;后面则是 “看神经元对哪些完整句子最敏感,然后通过分析句子结构自动提炼出它代表的词或短语概念”,后者更高效,减少了人工依赖。
- 将概念作为输入并标识学习概念的神经元的其他方法(神经元搜索)
- 对语料中每个句子,根据神经元激活值阈值生成二值掩码(binary mask)。同样为每个概念生成二值掩码(标记其在句子中是否出现)。计算神经元掩码与概念掩码的交并比(IoU),用于生成组合解释。
- 将神经元的原始激活值直接作为预测分数。计算每个神经元和每个概念的平均精度(Average Precision)。
- 聚焦于具有目标概念的实例(不是对语料库中的所有句子进行分析,而是先做一次 “筛选”—— 把要研究的 “概念”的句子挑出来。)计算神经元在这些实例上的平均激活值(Mean Activation Value)。
Probing-based Methods 基于探究
- Linear Classifiers:利用待分析模型生成的激活向量(可理解为模型中神经元的激活值组成的向量)来训练一个线性分类器,让它学习我们感兴趣的概念。分类器赋予神经元(作为分类器的特征)的权重,就代表了这些神经元对该概念的重要性分数。
- Gaussian Classifier :其核心假设是:神经元的激活值服从高斯分布(正态分布)。他们的具体做法是,在所有神经元的激活值上拟合一个 “多元高斯分布”(即同时考虑多个神经元之间的关联,建模它们的联合分布),并为单个神经元提取了专门的 “探测指标”(用于衡量该神经元与目标概念的关联)。缺点:需要有监督数据来训练分类器。
Causation-based methods 基于因果关系的方法
Ablation :消融的核心逻辑是通过改变单个神经元的值,来观察它对模型整体性能的影响,以此判断该神经元的重要性。具体操作是将目标神经元的值 “钳位”(固定)为 0 或某个特定值,然后对比模型在操作前后的性能变化。
它主要有两种应用方向:
- 无监督场景:识别模型层面的关键神经元目标是找到对整个模型性能至关重要的神经元。判断标准是:当某个神经元被消融(值被固定)后,模型的整体性能(如准确率)出现大幅下降,这类神经元就是 “关键神经元”。
- 有监督场景:识别特定输出类别的关键神经元目标是找到与模型某个具体输出类别(比如识别图片中的 “猫”)相关的神经元。判断标准是:当消融某个神经元后,模型对该类别的预测结果发生 “翻转”(比如原本预测为 “猫”,现在预测为 “狗”),这类神经元就是该类别对应的 “关键神经元”。此时,这个输出类别就是判断神经元重要性的 “参照概念”。
消融技术的主要局限在于难以识别 “神经元组” 的作用。
Knowledge Attribution Method:
- 模型(特指 Transformer 模型)所学习的事实性知识,是存储在其前馈神经网络(feed-forward neural networks)的神经元中的
- 使用了 “集成梯度(Integrated Gradient)” 这一归因技术,来计算并筛选出对表达某个 “关系事实” 最重要的那部分神经元(即 “top neurons”)。
- 只能识别出对预测重要的神经元,但无法直接知道这些神经元具体学习并代表了什么 “概念”。
Matrix Factorization
- 矩阵分解(MF)的核心是将一个大型矩阵分解为多个小型 “因子矩阵” 的乘积,其中每个 “因子” 代表一组功能相似的元素。
- 当输入一个句子时,模型各层的神经元激活值会构成一个激活矩阵。
- MF 可用于分解这个激活矩阵,分解后得到的每个 “因子” 对应一组神经元,这组神经元共同学习并编码了某个特定的 “概念”(比如语法结构、语义角色等)。
- 而且目前几乎没有学术研究将 MF 方法用于分析 NLP 模型
- 优势:与此前讨论的其他无监督解释方法相比,MF 的固有优势是能直接 “发现神经元组”(即通过分解自动将功能相似的神经元聚类),无需提前定义聚类规则。
- 核心局限 :
- 如何确定 “因子数量”(即需要将激活矩阵分解为多少个因子 / 神经元组)是一个非 trivial的问题,目前缺乏统一且有效的确定方法。
- “局部解释” 意味着 MF 只能解释单个输入(如一个句子)对应的模型激活模式,而无法提供 “全局解释”(即跨多个输入的、模型普遍遵循的规律)
Clustering Methods
- 聚类是另一种以无监督方式分析神经元组的有效方法。直觉是,如果一组神经元学习了一个特定的概念,那么它们的激活就会形成一个集群
- 局限性与矩阵分解方法类似,聚类数量是一个超参数,需要根据经验预先定义或选择。少量聚类可能导致同一组中出现不同的神经元,而大量聚类可能导致相似的神经元分裂成不同组
Multi-model Search
- 为同一任务训练的不同模型,会共享该任务的关键信息。如果一个概念对任务很重要,那么所有为该任务优化的模型都应该学习到它。因此,该搜索的目标是识别在不同模型间行为相似的神经元—— 这些神经元很可能编码了任务的核心概念。
聚合相关系数:为了从不同角度凸显模型特征,他们用四种方法对每个神经元的相关系数进行聚合,每种方法目标不同:
- 最大相关(Max Correlation):捕捉在多个模型中都 “强烈出现” 的概念(即该神经元与其他模型中某些神经元的相关性极高)。
- 最小相关(Min Correlation):筛选那些与很多模型都有相关性、但并非顶级相关的神经元(强调普遍性而非极致相关性)。
- 回归排序(Regression Ranking):寻找自身信息分散在其他模型多个神经元中的 “个体神经元”(即该神经元的功能由其他模型的多个神经元共同实现)。
- SVCCA:捕捉那些可能分散在 “比完整表示维度更低” 的信息(聚焦低维空间中的关键信息分布)。
局限性:即需要人类来解释这些被识别出的神经元的底层含义(比如这个神经元具体编码了什么概念)
评估方法
Ablation
- 在模型中的某个神经元前后判断其对输出效果的影响
Classification Performance
- 给定与某个概念相关的显著神经元后,评估其正确性的简单方法如下:
- 训练分类器:将这些显著神经元作为特征,训练一个分类器来预测目标概念。
- 性能对比:将该分类器的性能,与另外两个分类器进行比较 —— 一个用随机神经元训练,另一个用最不重要的神经元训练。
- 衡量有效性:通过这种相对性能对比,来衡量所选显著神经元的有效性(即它们是否真的与目标概念相关)。
- 给定与某个概念相关的显著神经元后,评估其正确性的简单方法如下:
- Information Theoretic Metric
- 用信息论指标(如互信息) 来解读深度学习 NLP 模型表示的思路。
- Concept Selectivity
- 概念选择性用于衡量单个神经元与 “发现的概念(discovered concept)” 之间的 “对齐程度(alignment)”,本质是评估神经元对目标概念的 “专属响应程度”。
- 判断一个神经元是否 “专门” 对某个语言概念敏感,而不受其他概念干扰。
- 计算方式
- 计算一个神经元在两类句子上的平均激活值:一类是 “包含目标概念的句子”,另一类是 “不包含目标概念的句子”。
- 用这两个平均激活值的差值作为 “选择性” 的量化结果。
- Qualitative Evaluation
- 将 “可视化” 作为一种非量化(定性)的评估工具,用于分析那些被选中的神经元。它不依赖具体数值,而是通过直观呈现来判断神经元的特性。
- 可视化单独使用时效果有限,与其他方法结合才能最大化其价值,具体体现在 “缩小搜索范围” 上:
- 结合概念搜索(Concept Search):可将分析范围缩小到 “对特定概念激活程度高的神经元”,避免无差别分析所有神经元。
- 结合基于探针的方法(Probing-based methods):能进一步聚焦到 “对这些高激活概念而言,功能最显著的神经元”,让评估更具针对性。
- 简单来说,可视化负责 “直观展示神经元在关注什么”,而其他方法负责 “告诉我们该看哪些神经元”,二者结合让对神经元的定性评估更高效、准确。
主要发现
Concept Discovery
- 神经元可以学习单词在输入句子中的位置
- 捕捉“否定”的神经元
- 捕获相关概念组的神经元,如西兰花、面条、胡萝卜
- 神经元捕获了核心语言概念,如名词、动词形式、数字、冠词等
- 负责概念的神经元数量因概念的性质而异
- 封闭类 (随着语言的发展,不会添加新词) 的神经元数量较少
- 开放类 (随着语言的发展,不断添加新单词,例如“chillax”,一个混合了“chill”和“relax”的动词。)的神经元数量较多
- 神经元表现出单义和多义行为其中少数神经元是单一概念所独有的,而其他神经元本质上是多义的,并捕获了多个概念
- 捕获了远程依赖性包括引号和括号
Architectural Analysis
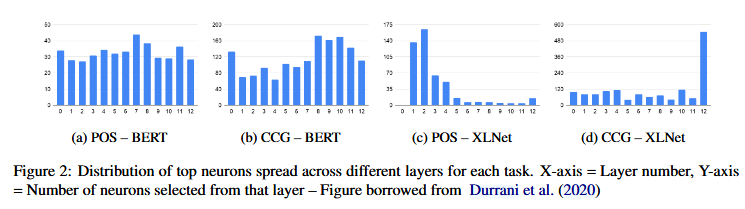
人类语言的结构是分层的,形态和音韵位于底部,其次是词位,然后是句法结构。发现捕捉单词形态的神经元主要存在于较低层和中间层,而学习句法的神经元则存在于较高层。
学习同形异义词的神经元分布在整个网络中
信息并不是在任何单个层中离散保存的,而是分布的,并且冗余存在于网络中
BERT(自动编码器)中的语言知识在整个网络中高度分布,而 XLNet(自回归)则由来自几层的神经元主要负责一个概念
神经元探测的应用
- 控制模型的行为
- 在 NMT 模型中确定了开关神经元,这些神经元对现在时动词积极激活,对过去时动词负激活。通过纵这些神经元的值,他们能够在推理过程中成功地将输出翻译从现在时更改为过去时
- 即时操纵输出,例如,它可用于针对种族和性别等敏感属性消除模型输出的偏差
- 模型蒸馏和效率
- 通过利用Transformer模型中的层和神经元特定冗余,对于模型的提炼和提升效率很有用。
- 域适应,提高泛化性
- 以针对在微调目标域模型时灾难性遗忘一般域的问题。
- 三步适应过程:
- 根据神经元的重要性对神经元进行排名
- 从网络中修剪不重要的神经元并使用师生框架进行重新训练
- 将网络扩展到其原始大小并向域内微调,冻结显着神经元并仅调整不重要的神经元。
- 使用这种方法有助于避免对一般域的灾难性遗忘,同时还可以在域内数据上获得最佳性能。
- 生成组合解释
未来问题和未来研究方向
- 目前大多数分析方法在寻找与某概念相关的神经元时,忽略了神经元之间的相互作用,仅关注单个神经元的贡献。
- 大量的解释研究依赖于人类定义的语言概念来探测模型。这些模型可能没有严格遵守人类定义的概念并学习有关该语言的新概念。
- 当前研究多聚焦于 “知识如何编码在模型表征中”,但对 “模型预测时是否真的使用这些编码的知识” 探索较少。
- 神经元解释的工作缺乏标准的评估基准,因此在相同模型上进行的研究无法比较。
- 神经元分析方法的理论基础以及它们旨在捕捉的关于给定概念的观点各不相同。这导致神经元的选择可能不会在所有方