TEST-TIME ADAPTATION FOR IMAGE COMPRESSION WITH DISTRIBUTION REGULARIZATION
TEST-TIME ADAPTATION FOR IMAGE COMPRESSION WITH DISTRIBUTION REGULARIZATION
1. 背景知识
现有基于先验的熵模型在跨域场景中因分布偏移导致联合概率分布不准确,进而影响性能。
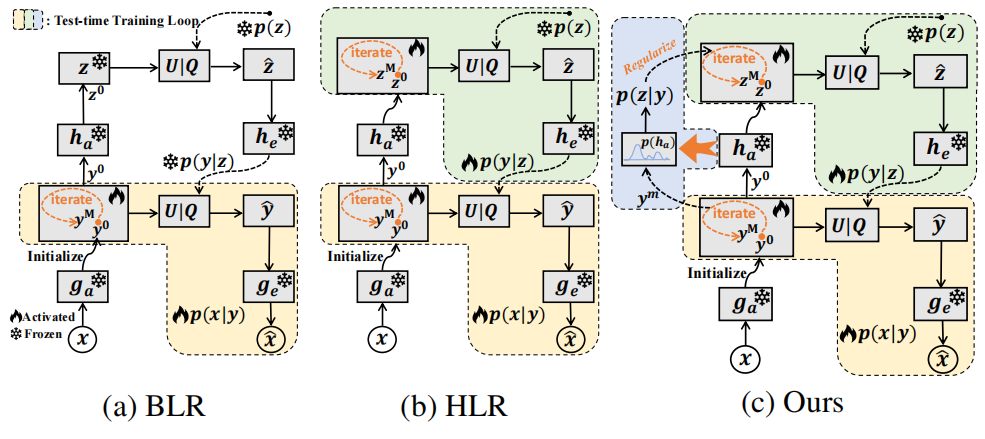
- 先验(Hyperprior):先验是一种用于图像压缩的模型,它通过引入一个额外的先验概率模型来捕获潜在表示中的空间依赖性。这个先验模型通常用于编码潜在表示的尺度信息,从而提高压缩效率。
- 熵模型:熵模型用于估计潜在表示的分布,以便进行有效的熵编码。在基于超先验的模型中,熵模型通常假设潜在表示的元素是独立的,但实际上这些元素之间可能存在统计依赖性。
传统联合优化潜在变量和辅助信息的方法(如HLR)在域内有效,但在跨域任务中因概率分布失配导致码率显著增加。
在跨域任务中,由于训练数据和测试数据的分布不同,潜在变量和辅助信息的概率分布也会发生变化。例如,自然图像和屏幕内容图像在统计特性上存在显著差异。当模型在自然图像上训练后,其潜在变量和辅助信息的概率分布是基于自然图像的特性学习的。然而,当模型应用于屏幕内容图像时,这些概率分布不再适用,导致模型无法准确地编码潜在变量和辅助信息。
2. 研究方法
边缘化近似角度揭示降解原因
- 边缘化近似:在图像压缩中,边缘化近似是指通过将联合概率分布 p(y,z) 近似为边缘概率分布 p(y) 和 p(z) 的乘积,来简化模型的计算。其中,y 表示潜在变量,z 表示超先验中的侧信息。
- 降解原因:在跨域场景中,由于源域和目标域之间的分布差异,基于超先验的熵模型无法准确地捕获潜在变量和侧信息的联合概率分布。这导致了边缘化近似的不准确,进而影响了码率(Rate)和重构质量(Distortion)的权衡(R-D性能)。具体来说,模型在编码潜在变量和侧信息时需要更多的比特来表示这些变量,从而导致码率显著增加
分布正则化方法
分布正则化通过对模型参数引入先验分布,分布正则化通过鼓励学习更好的联合概率近似,来减少跨域场景中的额外率消耗。
例如,通过分布正则化,可以调整潜在变量的分布,使其更接近目标域的分布,从而在跨域压缩中实现更好的率失真性能。
- zmt:表示在第 m 次迭代中更新的超先验(hyperprior)中的侧信息(side information)。侧信息 z 是从潜在变量 y 中提取的,用于帮助编码和解码过程。在跨域任务中,由于分布偏移,z 的概率分布可能与训练时的分布不同,导致编码效率下降。
- ymt:表示在第 m 次迭代中更新的潜在变量。潜在变量 y 是图像经过编码器变换后的表示,用于捕获图像的重要特征。在跨域任务中,由于分布偏移,y 的概率分布也可能与训练时的分布不同,导致编码效率下降。
β 的作用
- 控制正则化强度:β 用于控制正则化项 −logp(zmt∣ymt) 在总损失函数中的权重。较大的 β 值会增加正则化项的影响,从而更严格地限制模型的复杂度,有助于防止过拟合。
- 平衡模型复杂度和泛化能力:通过调整 β,可以平衡模型的复杂度和泛化能力。较小的 β 值可能会导致模型过拟合,而较大的 β 值可能会导致模型欠拟合。
- 最好0.1
- Dropout变分推断
- 文章利用dropout变分推断(DVI)作为贝叶斯近似,来估计潜在变量的后验分布。通过多次蒙特卡洛(MC)采样,估计后验分布的均值和方差,从而实现对潜在变量的优化。
- 例如,DVI通过随机丢弃神经元的方式,模拟潜在变量的不确定性,为潜在变量的优化提供了更准确的估计。
3. 实验与结果
3.1 数据集
- 文章使用了六个不同的数据集,包括自然图像(Kodak)、屏幕内容图像(SIQAD、SCID、CCT)、像素风格游戏图像和绘画图像(DomainNet)
3.3 性能评估
3.3.1 R-D曲线与BD-rate
- 通过计算不同方法的峰值信噪比(PSNR)和每像素比特数(bpp),绘制R-D曲线,并计算(BD-rate)来评估性能。BD-rate越低,表示性能越好。
思考
超参数β和MC采样次数T对性能影响显著(如表3),但文中未提供自动调参方案。此外,不同数据集可能需特定参数配置,限制了方法的即插即用性。
dropout变分推断是什么意思,我的理解是测试的时候也用dropout, 只是换了种解释方法