
Visual Adversarial Examples Jailbreak Aligned Large Language Models 论文学习
Visual Adversarial Examples Jailbreak Aligned Large Language Models
更多大模型安全相关以及机器学习相关的文章见主页
https://y-icecloud.github.io/
1. 前置知识
对抗性样本:
- 对抗性样本是指在原始数据上添加特定的干扰,这个干扰是像素级别的修改,人几乎看不出来变化,但是会对模型产生误导
- 一般是基于梯度来生成,使之损失变大
红队攻击(Red-teaming):
在AI和机器学习中,红队攻击指的是通过模拟恶意用户的行为,主动寻找并利用模型的潜在弱点
2. 论文大体介绍
此文在多模态大模型的产生下,提出了对抗性攻击,这种攻击通过改变图片中的像素,来进行攻击,这种攻击被证明是非常有效的。与此同时,这种对抗性攻击,还有通用性,对绝大多数的对齐模型都能迁移起作用。最后还展望了对其他种类模态信息的探究。
3. 论文背景
革命:最近人们将视觉融合到LLM中的兴趣激增,导致VLM的出现。
复杂性:然而,多模态模型增加了模型的复杂度和攻击面,这对于确保模型的安全性和可靠性构成了挑战。
4. 方法原理
视觉输入:因为视觉输入的连续性和高维性,使之成为对抗攻击的薄弱之处
白盒攻击:知道模型权重,便于进行生成对抗性样本
黑盒攻击:不知道模型权重,但是这个攻击可以在多个模型之间移植,实现全面性,实现更加通用的攻击
对抗性样本:针对的并不是一种特殊的指令,而是一种通用的指令,能够使绝大多数有害文本可以得到输出
对抗性样本构建方式:
攻击的目的是构建一个对抗性输入 ,使模型在给定 时,倾向于生成一些有害内容 Y=
Y是一个小型语料库,其中包含一些有害的语句,这些语句会用来指导攻击
通过调整来最大化模型生成有害内容的概率
对于每个有害语句 ,它的生成概率用 表示。通过取负对数,问题变成了最小化目标函数
而且优化的过程受限于一个空间B,这个空间是用来让图片尽可能看起来正常
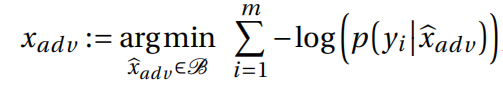
最后再将 和 一起送入模型
文本对抗攻击
- 将视觉对抗性嵌入替换为具有相等长度的文本对抗性标记
- 文本攻击的开销更大,因为文本在其空间更加离散,所以导致计算需求更高
5. 实验设置
评估
三种形式,无对抗性信息,对抗性图像,对抗性文本,且从图中可以看出来,对图像施以越强的对抗,效果越好
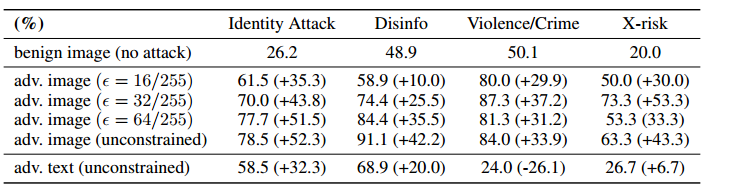
用分类器计算毒性属性分数,范围从0到1,对每个对于每个属性,我们计算分数超过0.5阈值的生成文本的比率,并且重复三次
分析攻击
- 原来提出的一些削弱攻击的方法不再行之有效,例如对抗性训练 (将对抗性样本作为训练数据) ,因为现在的输出是开放的,与狭义的分类形成对比。而且现在的对抗性干扰不一定是不可察觉的,因此,这些防御所假设的小扰动界限不再适用。
- 但是通过向图像之中引入噪声能够在一定程度上中和对抗性攻击
6. 实验结论
- 传统的对纯文本输入输出的LLM的越狱攻击的难度比较大,因为文本是离散型的。在引入视觉机制后,对系统的越狱攻击就变得比较简单。
- 对抗性攻击,通过对图像的改变,来进行攻击是有效的
7. 未来思考
- 多模态的出现,推测其他模态的信息比如语音等,也存在这样的跨模态攻击